Loading...
Loading...
Cinute Digital
Head Office (CDPL)
Study Center MeghMehul Classes (Vasai)





ISO 9001:2015 (QMS) 27001:2013 (ISMS) Certified Company.
© 2026 Cinute Digital Pvt. Ltd. — All Rights Reserved.

A strategic guide for engineering leaders on utilizing Python's Pandas library to process enterprise testing data, eliminate QA bottlenecks, and build autonomous workflows.
A strategic guide for engineering leaders on utilizing Python's Pandas library to process enterprise testing data, eliminate QA bottlenecks, and build autonomous workflows.
In the modern enterprise ecosystem, software testing does not just generate bugs; it generates massive, complex datasets. For CTOs and Engineering Leads, the ability to rapidly parse and act upon this data dictates speed-to-market and ROI. While traditional spreadsheets collapse under the weight of millions of automation log lines, Real-World Pandas data manipulation offers a scalable, programmatic solution. By leveraging Python's premier data analysis library, engineering teams can instantly aggregate test results, identify hidden regression patterns, and feed clean data into Agentic AI models. This isn't just about writing cleaner code; it is about transforming raw testing exhaust into a highly actionable strategic asset that drives autonomous QA workflows and secures your bottom line.
The defining challenge of modern CI/CD pipelines is not executing tests it is interpreting the aftermath. When a nightly automation suite consisting of 10,000 UI, API, and unit tests finishes executing, it leaves behind a sprawling mess of XML reports, JSON payloads, and unstructured server logs.
The Problem: Most QA teams rely on fragmented dashboards or manual spreadsheet exports to figure out what went wrong. When a critical release is pending, engineers spend hours sifting through false positives, environment timeouts, and raw data strings just to isolate a single legitimate defect.
The Agitation: This manual data wrangling causes severe operational friction. Release cycles are delayed, technical debt accumulates invisibly, and highly paid automation engineers waste their cycles acting as human parsers rather than building robust test frameworks. Furthermore, without historical data analysis, "flaky tests" (tests that pass and fail randomly) are ignored, eroding the team's trust in the entire automation pipeline. If your data analysis is slow, your market response is slow.
The Solution: The integration of the Python Pandas library into your QA reporting infrastructure. By treating test results as a data science problem rather than a basic reporting task, you can automate the extraction, transformation, and loading (ETL) of test data.

Pandas is fundamentally an in-memory data manipulation tool built on top of NumPy. It introduces the Data Frame a highly efficient, two-dimensional data structure that handles tabular data with SQL-like efficiency but with the flexibility of Python.
For an enterprise QA strategy, Pandas provides three critical business advantages:
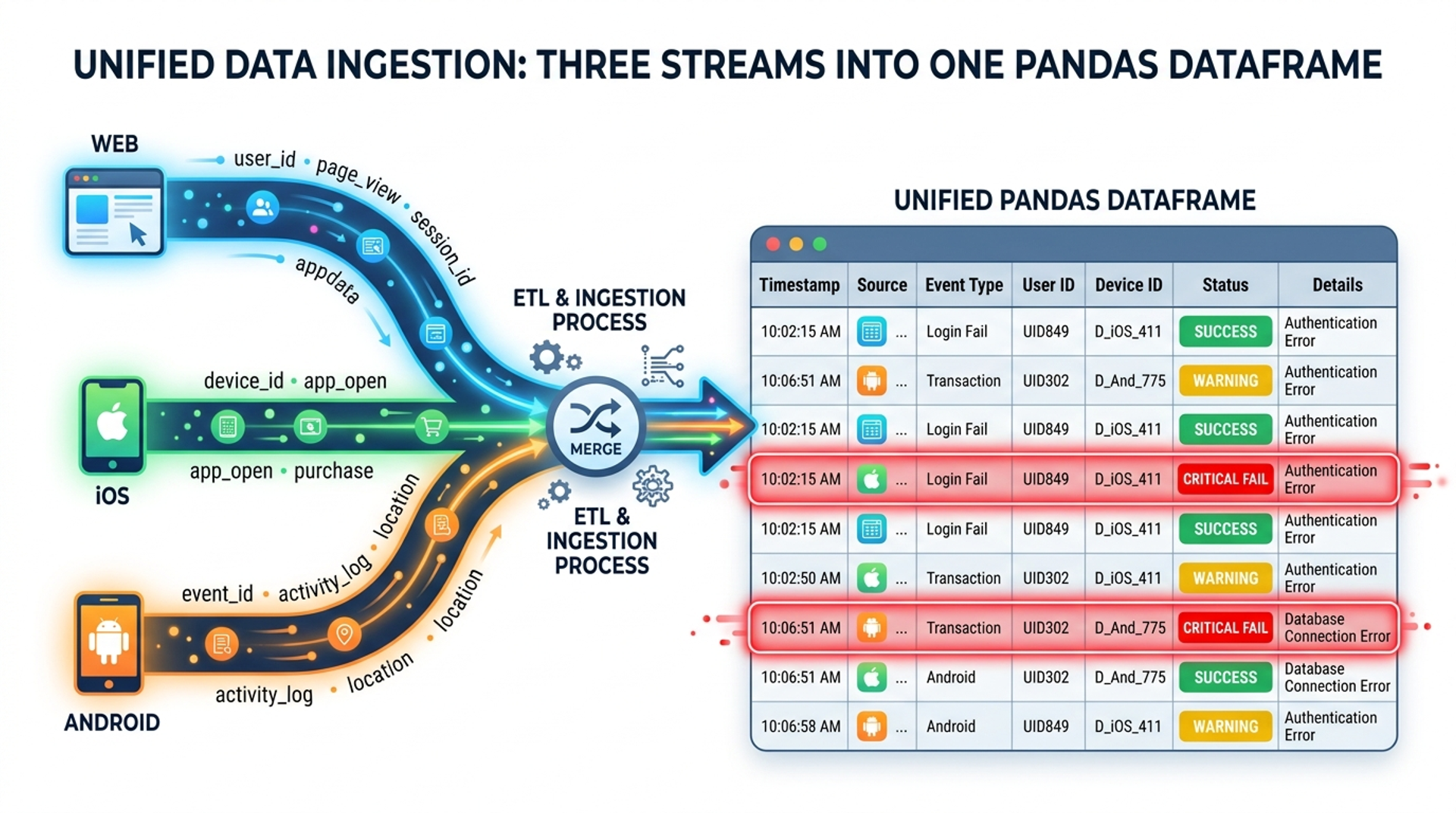
Consider a scenario where your team runs parallel tests across Web, iOS, and Android. Each platform generates its own distinct report. A manual QA manager would spend hours cross-referencing these failures. With Pandas, this is automated.
By importing the pandas library, engineers can utilize the pd.concat() and pd.merge() functions to unify these datasets.
<pre><code>
import pandas as pd
import glob
path = r'./test_reports'
all_files = glob.glob(path + "/*.csv")
This simple script replaces hours of manual data collation. It allows your automation testing services team to immediately pinpoint whether a login failure is isolated to Android or is a catastrophic backend failure affecting all platforms.
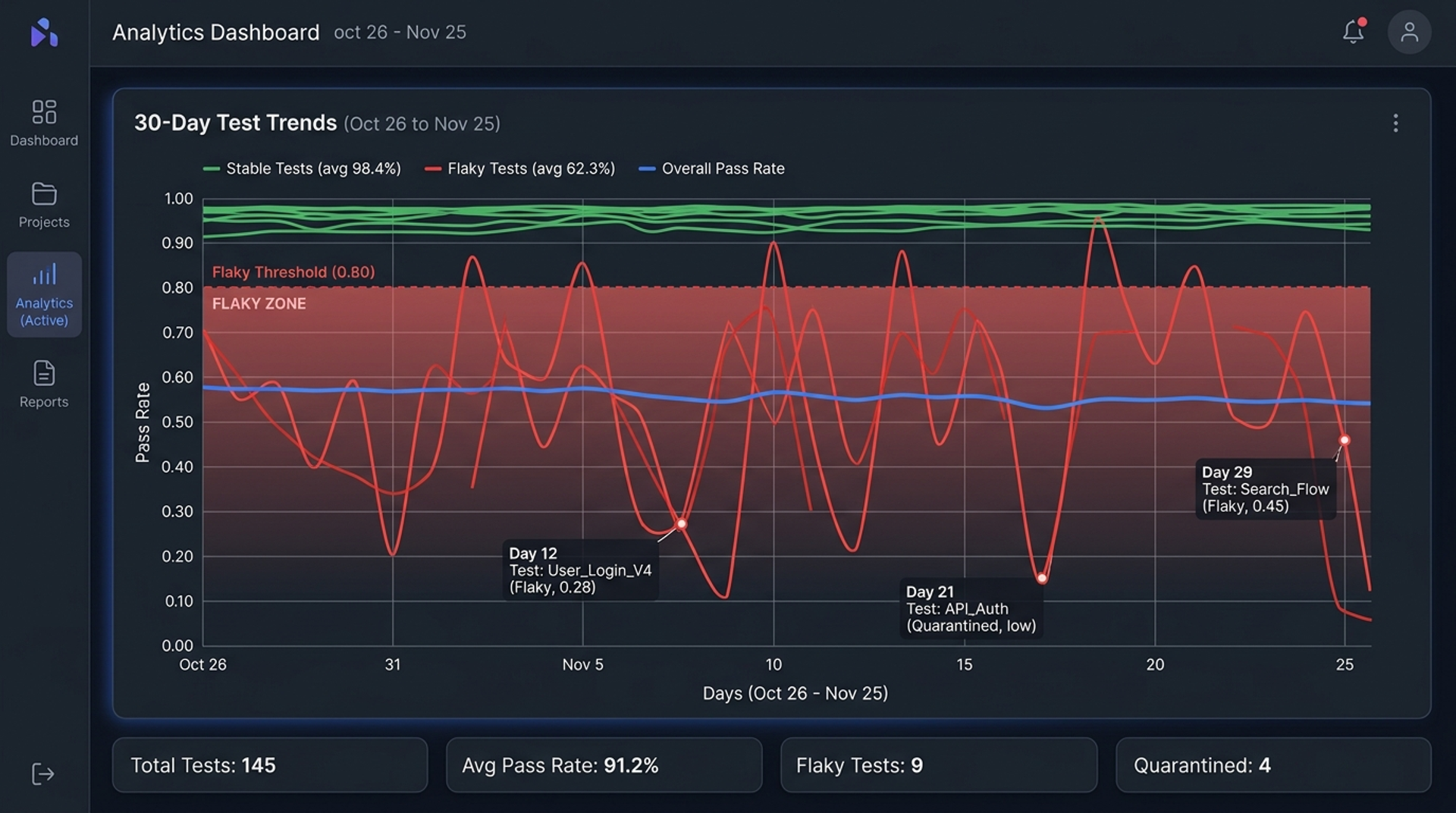
Flaky tests are the silent killers of CI/CD momentum. A test that passes 80% of the time and fails 20% of the time usually indicates a race condition or a fragile environment, not necessarily a broken feature. However, looking at a single day's report will not reveal a flaky test. You need historical data manipulation.
Using Pandas, we can group historical test executions and calculate the variance in their pass/fail status over time.
<pre><code>
Isolate tests that pass between 10% and 90% of the time (The Flaky Zone)
By identifying these tests programmatically, engineering leads can quarantine them, ensuring the main pipeline remains green while the QA team investigates the instability. This drastically reduces false alarms and improves the overall performance testing solutions workflow.
Often, the most valuable data is buried deep within raw, unstructured server or application logs generated during a test run. A test might say "Failed," but the reason is trapped in a 50MB text file.
Pandas excels at text data manipulation using its .str accessor, allowing teams to apply Regular Expressions (RegEx) across millions of rows instantly.
<pre><code>
This capability transforms raw text into structured metrics, allowing teams to track error density over time and integrate these insights into broader data analytics course.
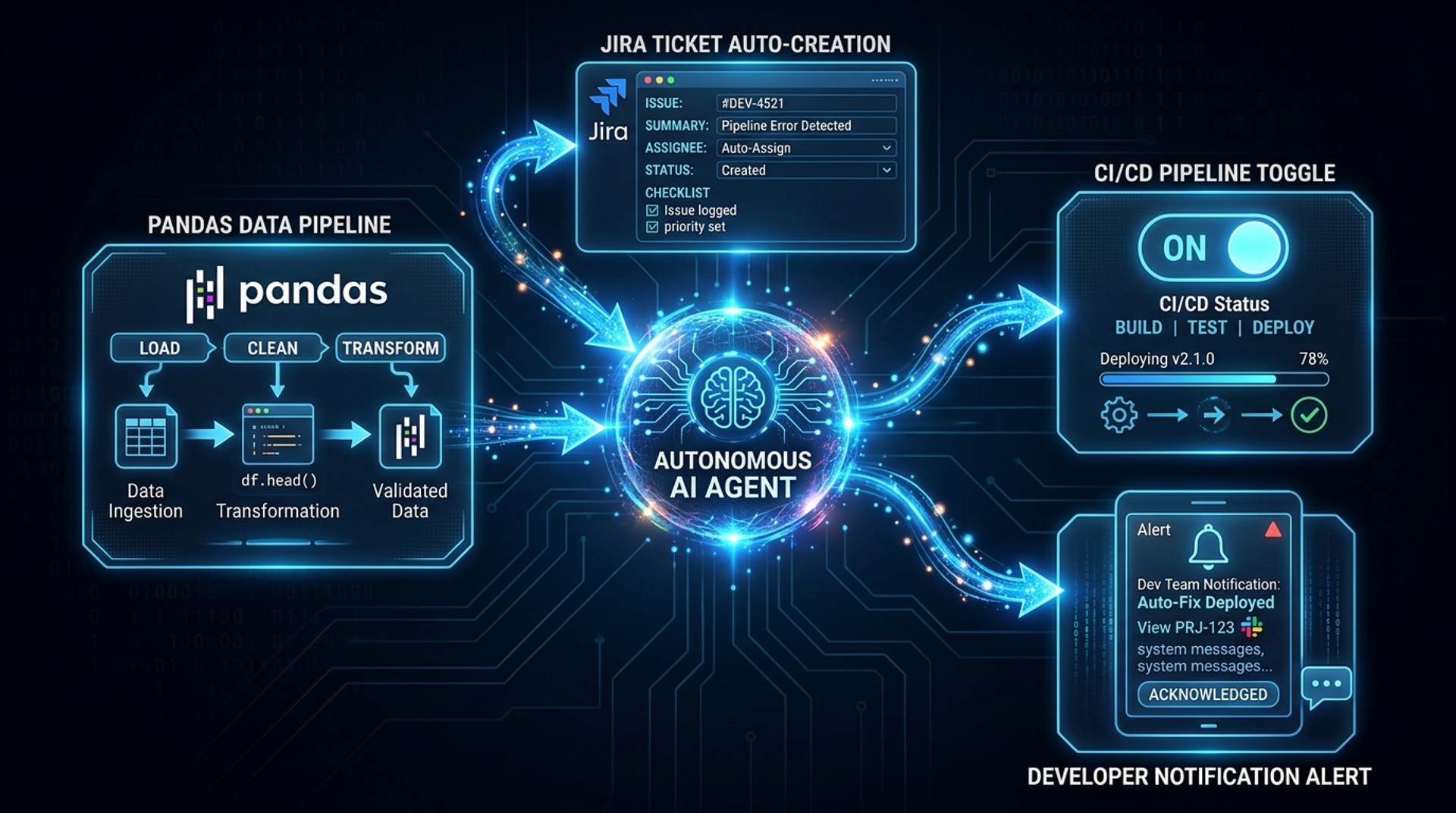
The true power of real-world Pandas data manipulation is realized when it serves as the foundation for Agentic AI.
An Agentic Workflow in software testing involves AI agents that can act autonomously based on data triggers. For example:
This level of autonomy is impossible without the rigorous data preparation that Pandas provides. It shifts your QA department from a cost center into a highly optimized, automated risk-management engine, which is a core pillar of modern digital transformation consulting.
When dealing with enterprise-scale data, how you write your Pandas code matters. A common mistake made by junior analysts is treating a Pandas DataFrame like a standard Python list and using for loops to iterate through rows (e.g., using iterrows()).
Strategic Insight: Iteration in Pandas is an anti-pattern.
To achieve maximum performance, teams must rely on Vectorization. Vectorization pushes the mathematical operations down to the highly optimized C-level code that underpins Pandas, allowing operations to occur simultaneously across entire arrays.
pd.to_datetime(df['Timestamp']) to convert the entire column in a fraction of a second.Ensuring your teams adhere to vectorized operations guarantees that as your test suites grow, your data analysis remains instantaneous, supporting seamless custom software development lifecycles.
Pandas does not exist in a vacuum. Once the data is manipulated and the insights are extracted, it must be visualized for stakeholders.
Modern engineering teams frequently decouple the heavy data processing (Python/Pandas) from the frontend presentation layer. By setting up automated Python scripts that run post-test, Pandas can clean the data and export it via a lightweight API or directly into a modern cloud database.
From there, frontend frameworks like Next.js can be used to build lightning-fast, server-side rendered dashboards. This allows CTOs to log into a premium, responsive web interface and view real-time QA metrics without ever needing to look at the underlying Python code. This architectural separation of concerns ensures that the heavy lifting is handled by Pandas, while the user experience remains flawless—a standard practice in advanced managed IT solutions.
In the real world, data is dirty. Network timeouts occur, databases drop connections, and test logs get truncated. When combining datasets, you will inevitably encounter NaN (Not a Number) values. How you handle these missing values dictates the accuracy of your QA metrics.
Pandas provides robust methods for dealing with data gaps:
.dropna(): Used to drop rows that contain missing critical data. If a test result is missing its 'Status', it is useless for analysis and should be dropped..fillna(): Used to impute missing values. For instance, if an optional 'Execution_Time' field is missing, you might fill it with the median execution time of that specific test to maintain statistical balance.A rigorous technical SEO audit relies on complete data, and similarly, a technical QA audit requires meticulous handling of missing information to ensure decision-makers are looking at the true picture.
Q: Can Pandas handle datasets larger than my computer's RAM?
A: Pandas processes data in-memory. If your log files exceed your available RAM, Pandas will struggle. For massive, out-of-core datasets, we recommend using Pandas in conjunction with libraries like Dask or Polars, or utilizing chunking (chunksize parameter in read_csv) to process the data in manageable pieces.
Q: Is it better to perform data manipulation in the database using SQL or in Python using Pandas?
A: It depends on the operation. Simple filtering, grouping, and aggregations are often faster when pushed down to the SQL database level. However, for complex statistical analysis, machine learning preparation, or merging data from diverse, non-database sources (like JSON payloads and XML test reports), Pandas is far superior and more flexible.
Q: How does Pandas integrate with CI/CD tools like Jenkins or GitHub Actions?
A: Python scripts utilizing Pandas can be executed as a standalone build step within your CI/CD pipeline. After your automated tests finish, the pipeline triggers the Python script, which ingests the freshly generated reports, manipulates the data, and can automatically Slack the summarized results or fail the build if error thresholds are exceeded.
Q: Do I need a dedicated Data Scientist to use Pandas for QA?
A: No. While Pandas is incredibly deep, the functions required for QA data manipulation (reading files, filtering, merging, and basic grouping) can be mastered by existing Automation Engineers or SDETs (Software Development Engineers in Test) with basic Python knowledge.
In an era where software complexity is accelerating exponentially, traditional methods of analysing test results are no longer viable. The bottleneck is no longer how fast we can run tests, but how fast we can make sense of the data they produce.
Real-world Pandas data manipulation is not just a technical skill; it is a strategic necessity for modern engineering teams. By adopting Pandas, CTOs and QA Leads can conquer the data deluge, uncover hidden patterns in flaky tests, and build the structured data pipelines necessary for Agentic AI. Moving from manual spreadsheet analysis to programmatic Python data manipulation empowers your organization to release faster, mitigate risk proactively, and maintain a decisive competitive edge in the market. Stop reacting to raw test data start engineering it.

Shoeb Shaikh is a seasoned Software Testing and Data Science Expert and a Mentor with over 14 years of experience in the field. Specialist in designing and managing processes, and leading high-performing teams to deliver impactful results.
