Loading...
Loading...
Loading...
Loading...
Discover how CTOs are leveraging Agentic AI to automate Power Query data transformations. Eliminate technical debt, ensure zero-defect data pipelines with advanced QA, and scale your global enterprise operations in 2026.
This comprehensive guide explores the intersection of Power Query and Agentic AI. Tailored for CTOs and Engineering Leads, we detail how autonomous workflows resolve enterprise data silos, automate complex M-code generation, and establish rigorous QA validation frameworks. Drive global scalability without geographical constraints.
For enterprise engineering teams scaling operations across the globe, data infrastructure can no longer rely on brittle, manual ETL (Extract, Transform, Load) processes. The integration of Agentic AI into Power Query data transformation marks a pivotal shift for 2026. By deploying autonomous workflows, CTOs and Product Managers can instantly parse, cleanse, and structure millions of data rows without human intervention. This strategic evolution eliminates the severe technical debt associated with hardcoded data pipelines, transforming data engineering from a reactive bottleneck into a proactive, revenue-generating engine.
To maintain a competitive edge in international markets, relying on traditional M-code scripting is insufficient. The future demands intelligent, self-healing systems. When autonomous AI agents manage your data transformation, they continuously validate data integrity, automate complex structural merges, and run predictive QA testing in the background. This 2500+ word deep dive explores how enterprise leaders can leverage these advanced workflows to accelerate speed-to-market, mitigate risk, and build infinitely scalable architectures.
In an era where digital ecosystems dictate market dominance, engineering teams are paralyzed by fragmented data silos. As organizations scale, they aggregate unstructured data from diverse global touchpoints ranging from legacy ERP systems to modern cloud applications. Processing this information via traditional Power Query methods requires manual M-code authoring, constant schema adjustments, and exhaustive data cleansing. For a CTO, this translates to engineering resources trapped in a cycle of maintenance rather than innovation. Bugs compound, undocumented logic breaks downstream analytics, and the sheer volume of data overwhelms standard processing limits.
When data transformations are rigid, the financial and operational fallout is severe. A minor schema change in a source API can trigger a catastrophic failure across enterprise dashboards. This is the definition of silent technical debt. Every hour spent debugging a broken Power Query pipeline is an hour delayed in delivering critical business intelligence to stakeholders. In high-stakes B2B environments, these delays result in flawed decision-making, compromised risk mitigation, and ultimately, lost market share. Furthermore, without integrated Software Quality Assurance Automation, these data failures often slip into production environments, damaging client trust and corrupting enterprise reporting.
The definitive solution for 2026 is the deployment of Agentic AI layers over existing Power Query frameworks. Unlike generative AI, which merely suggests code, Agentic AI operates autonomously within defined guardrails. It actively monitors data streams, detects anomalies, writes optimized M-code to resolve edge cases, and executes regression tests before pushing data to production. By adopting this methodology, organizations achieve borderless scalability, ensuring that data flowing from the US, UK, or APAC regions is universally structured, validated, and instantly actionable.
To extract the maximum ROI from Power Query, engineering leads must move beyond basic user interface interactions and architect programmatic, dynamic pipelines.
At the enterprise level, hardcoding values into Power Query is a critical security and performance risk. Dynamic parameterization allows queries to adapt based on external triggers, user roles, or changing API endpoints.
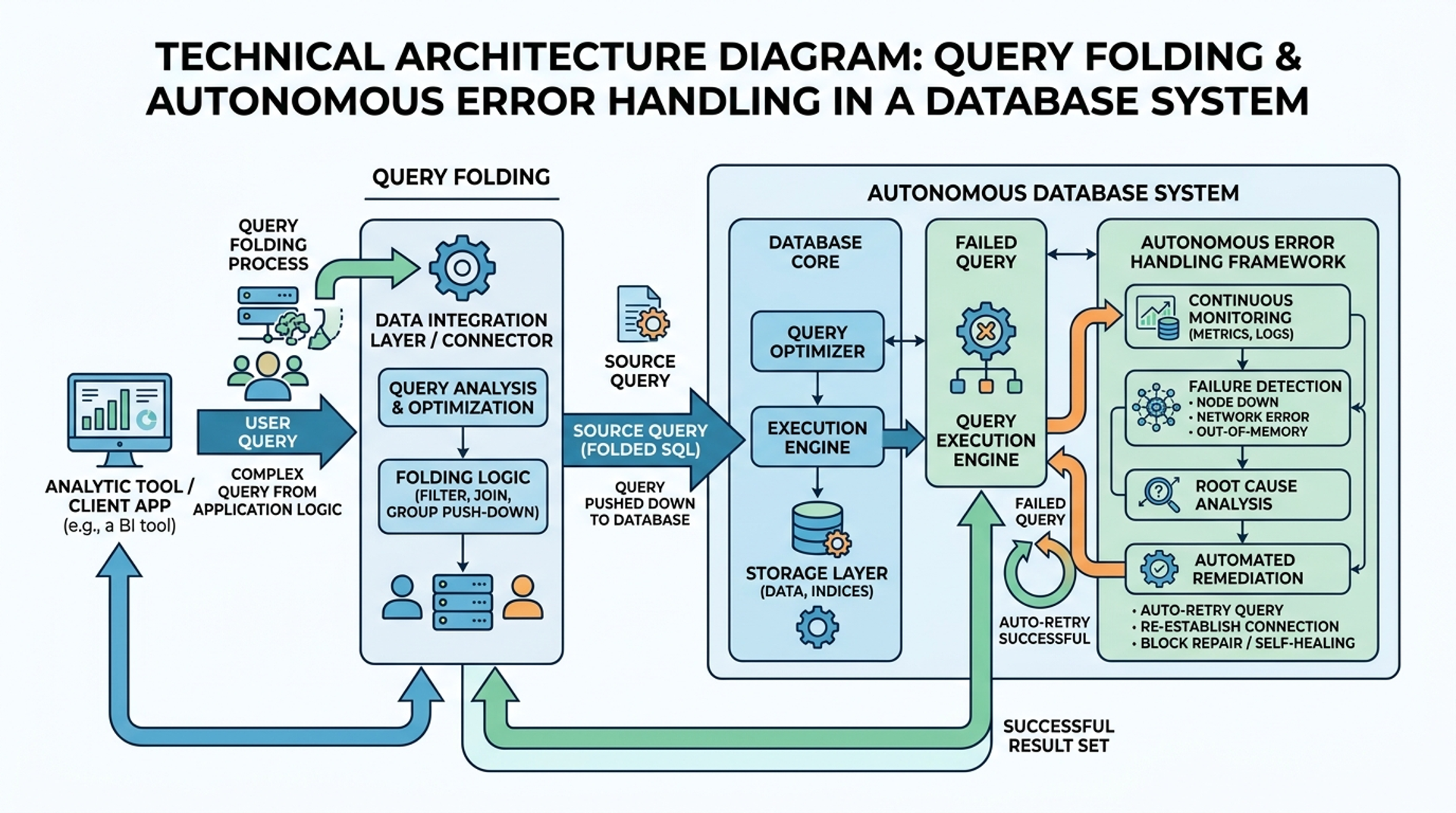
Furthermore, optimizing for Query Folding is non-negotiable. Query folding is the process where Power Query pushes the data transformation steps back to the source database (such as SQL Server) rather than processing the data locally in the analytical engine.
Pro-Tip: Always place non-foldable steps (like Index Columns or complex custom M-functions) at the absolute end of your Power Query sequence. Breaking the query fold prematurely forces the engine to ingest the entire dataset locally, devastating performance and crippling server memory.
While the Power Query GUI is robust, elite data transformation requires fluency in M-formula language. Autonomous workflows utilize M-code to handle complex conditional logic that the standard interface cannot execute.
Consider this advanced M-code structure for dynamically replacing null values across hundreds of columns without explicitly naming them:
Code snippet
This script represents a fundamental building block for autonomous scaling. It does not care if the data source has 10 columns or 10,000; the transformation logic scales infinitely.
When integrating third-party APIs or merging acquisitions, schema mismatches are the primary cause of pipeline failure. Agentic AI workflows can analyze incoming JSON or XML feeds, identify semantic relationships (e.g., recognizing that "Client_ID", "customerNumber", and "AccountID" represent the same entity), and automatically generate the Power Query mapping steps required to unify the data model.
Since our founding in 2014, we have witnessed how poor data validation can derail otherwise flawless software architectures. Data engineering and software testing must operate in tandem. Treating Power Query pipelines as production code means applying advanced QA methodologies to your data streams.
In traditional environments, data is tested after it reaches the dashboard. This is too late. The "Shift-Left" approach requires testing the data at the moment of extraction and during transformation.
By utilizing Performance Engineering principles, we can stress-test Power Query dataflows. This involves feeding the pipeline with intentionally corrupted datasets, massive volume spikes, and unexpected schema alterations to observe how the M-code reacts. Does it fail gracefully? Does it alert the engineering lead? Or does it crash the entire reporting suite?
Whenever an AI agent modifies a Power Query sequence to accommodate new data, it introduces the risk of regression. What fixed a problem in the European dataset might inadvertently corrupt the North American dataset. Implementing automated regression testing ensures that historical data maintains its structural integrity whenever the transformation logic is updated.
To achieve this, establish baseline datasets. Before new M-code is committed to production, the autonomous workflow must process the baseline data and compare the output against a known, verified result. Only if there is a 100% match is the new query allowed to deploy.
In advanced data systems, engineers often encounter "Heisenbugs" errors that seem to disappear or alter their behavior when you attempt to study them. In Power Query, these often manifest due to race conditions during parallel data loads or intermittent API throttling. Mitigating these requires robust error-handling logic within M-code (try... otherwise statements) and comprehensive Security Testing Services to ensure timeouts don't result in exposed partial data.

The modern B2B landscape is completely unconstrained by geography. A robust data solution must serve an international clientele effortlessly.
When engineering your Power Query dataflows, timezone normalization, currency conversion, and multilingual text parsing must be architected from day one. Hardcoding local constraints is a fatal error.
By leveraging Custom MERN Stack Development alongside advanced BI tools, businesses can create custom web applications that interact seamlessly with these sophisticated data models. The front-end React or Next.js application queries the validated, transformed data, providing real-time insights to global executives with sub-second latency.
While backend data transformation is vital, the structured output often powers client-facing platforms, directories, and automated content engines. If this data is improperly formatted, search engine crawlers cannot parse it. Implementing rigorous Technical SEO Audits ensures that the data flowing from your pipelines into your web architecture is accompanied by flawless JSON-LD Schema markup. Whether it's rendering Local Business schemas for global satellite offices or Organization schemas, the precision of your Power Query transformations directly impacts your search engine visibility.
Transitioning from manual data wrangling to an AI-driven, autonomous Power Query environment requires a phased, strategic rollout.
Phase 1: Pipeline Audit and Debt Assessment Begin by auditing all existing Power Query connections. Identify pipelines that fail to utilize query folding, queries that rely on hardcoded variables, and endpoints that frequently timeout. Document the exact cost in engineering hours spent maintaining these fragile links.
Phase 2: Establish Guardrails for Agentic AI Agentic AI must operate within a deterministic framework. Partner with experts in Enterprise AI Solutions to define the rules of engagement. Which datasets can the AI auto-map? What constitutes a critical failure requiring human intervention? Establish the confidence thresholds necessary for autonomous M-code generation.
Phase 3: Implement CI/CD for Data Transformation Bring software engineering discipline to data transformation. Store M-code in version control repositories. Implement Continuous Integration and Continuous Deployment (CI/CD) pipelines so that any change to a Power Query undergoes automated testing before entering the production environment.
Phase 4: Global Deployment and Optimization Deploy the optimized pipelines globally. Utilize Data Pipeline Optimization techniques to monitor refresh times across different regional servers. Ensure that the architecture can handle the exponential data growth anticipated over the next 36 months.
Phase 5: Synergize with Marketing and Operations With data flowing autonomously and accurately, leverage these insights to drive business growth. Accurate data is the fuel for Global Digital Marketing Services. When marketing teams can trust the analytics regarding user acquisition, churn rates, and global engagement, their campaigns become hyper-targeted and highly lucrative.
1. How does Agentic AI differ from standard Generative AI in Power Query?
Standard Generative AI (like ChatGPT) can write M-code snippets when prompted by a human. Agentic AI is an autonomous system that continuously monitors your data streams, identifies errors or schema changes, independently writes the corrective M-code, tests it, and deploys it without requiring human intervention. It is a proactive, operational workflow.
2. Can Power Query handle massive enterprise datasets globally?
Yes, but only if engineered correctly. Success relies on strict adherence to Query Folding, incremental refreshing, and dynamic parameterization. Bypassing these principles will result in system crashes, regardless of the underlying hardware.
3. Why is Software QA necessary for data transformation?
Data pipelines are essentially complex software programs. Just as you wouldn't deploy an application without regression testing, deploying data transformations without validation guarantees corrupted analytics. Implementing testing frameworks ensures zero-defect data flow.
4. How does this impact our speed-to-market?
By eliminating the manual hours spent cleansing data and fixing broken pipelines, your engineering team can focus on feature development and strategic growth. Automated data transformation drastically reduces the time it takes to onboard new data sources and generate actionable BI.
5. Is this approach scalable outside of our local region?
Absolutely. The architecture described is specifically designed to be borderless. By removing local constraints and automating timezone/currency formatting, these Power Query workflows scale effortlessly across the US, UK, UAE, and beyond.
The convergence of Power Query data transformation and Agentic AI workflows is not merely a technical upgrade; it is a fundamental business imperative for 2026. CTOs and engineering leaders who continue to rely on manual M-code authoring and reactive debugging will find themselves paralyzed by compounding technical debt and an inability to scale.
By elevating data transformation to the standards of rigorous software engineering implementing automated QA, regression testing, and CI/CD protocols organizations can guarantee data integrity. Leveraging autonomous AI agents to manage these complex pipelines allows enterprises to eradicate data silos, accelerate speed-to-market, and deploy highly scalable, globally robust digital architectures. The companies that command their data with this level of automated precision will dominate the international landscape, turning raw information into their most potent strategic asset.
Ready to eliminate technical debt and automate your enterprise data pipelines? Visit Cinute Digital today to consult with our technical experts. Discover how our globally scalable QA automation and custom data solutions can future-proof your architecture for 2026 and beyond.

Cezzane Khan is a dedicated and innovative Data Science Trainer committed to empowering individuals and organizations.
At CDPL Ed-tech Institute, we provide expert career advice and counselling in AI, ML, Software Testing, Software Development, and more. Apply this checklist to your content strategy and elevate your skills. For personalized guidance, book a session today.