Loading...
Loading...
Cinute Digital
Head Office (CDPL)
Study Center MeghMehul Classes (Vasai)





ISO 9001:2015 (QMS) 27001:2013 (ISMS) Certified Company.
© 2026 Cinute Digital Pvt. Ltd. — All Rights Reserved.
Want to extract data from any website using just 20 lines of Python? This beginner-friendly tutorial teaches you web scraping with BeautifulSoup step-by-step no prior experience needed. Walk away with working code, ethical scraping rules, and a clear career roadmap for the Indian job market.
Want to break into Python development or data science? This step-by-step BeautifulSoup tutorial teaches you to build a working web scraper in 15 minutes, avoid 5 common beginner mistakes, and understand the realistic ₹5–20 LPA career ladder for scraping skills across India
Every minute, Indian e-commerce platforms list over 4,000 new products. Real estate portals refresh thousands of properties. Job boards drop fresh openings. All of this data sits behind web pages visible to anyone, but locked inside HTML.
Now imagine you could extract that data automatically, save it to a spreadsheet, and analyze it for trends. That is exactly what web scraping with BeautifulSoup lets you do, and you can build your first scraper in under 30 minutes.
This tutorial is for absolute beginners. You will learn what BeautifulSoup actually does, write your first working scraper, understand the rules of ethical scraping, and see how this skill opens up career paths in data science, analytics, and Python development across India. No prior scraping experience needed just a laptop and curiosity.
By the end of this guide, you will have real code running on your machine and a clear picture of where this skill takes you next.
Web scraping is the process of writing a program that visits a website, reads its content, and pulls out specific information automatically. Think of it like a robot intern who can read 10,000 product listings before lunch.
BeautifulSoup is a Python library that makes this easy. When a web page loads, your browser converts raw HTML into the visual page you see. BeautifulSoup does the same conversion but keeps it as a searchable structure your Python code can navigate.
Here's a relatable analogy. Imagine you have a 500-page magazine and you need every author name and article title. Reading manually takes hours. But what if each page had clear labels <author>, <title> and you had a tool that could jump to those labels instantly? That is BeautifulSoup. Websites already have these labels (HTML tags), and BeautifulSoup is the tool that reads them.
A typical workflow has three players working together:
requests : fetches the raw HTML from a URL (like opening the page in a browser)BeautifulSoup : parses that HTML into something Python can searchYou do not need to "view source" or copy-paste anything. BeautifulSoup reads the structure for you and hands you clean data.
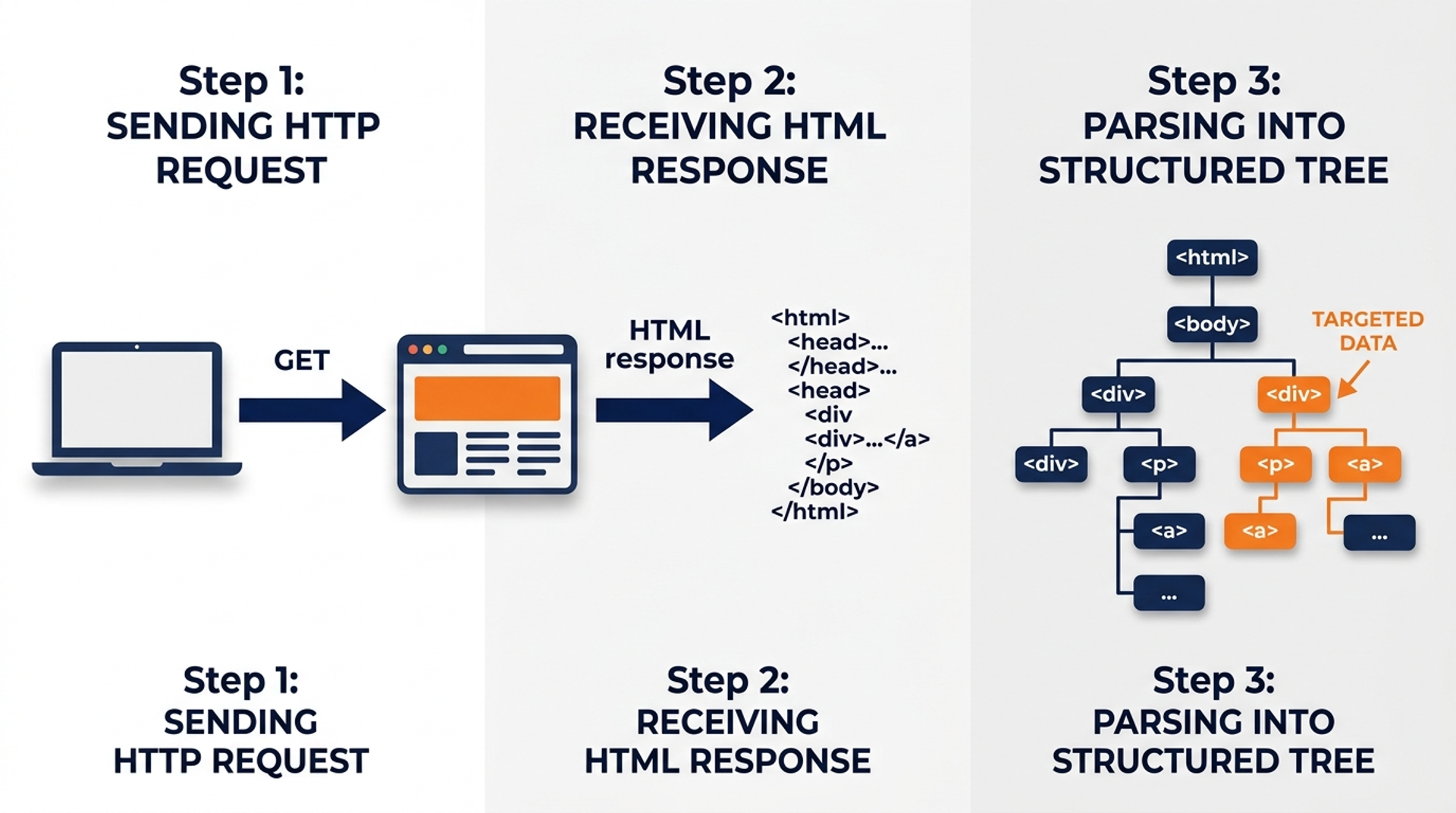
Key Takeaway: BeautifulSoup is not magic it is a translator that converts messy HTML into clean, searchable Python objects.
If you are starting from zero, CDPL's hands-on Python Programming course covers everything from syntax to libraries like BeautifulSoup and requests
India's data economy is exploding. According to NASSCOM, the country's data analytics and AI services sector crossed USD 70 billion in revenue in 2025, and a big chunk of that work starts with one question: where does the data come from? Often, the answer is web scraping.
Look at how Indian companies use it daily:
This means Python developers with scraping skills are genuinely in demand, not just on paper. A quick scan of Naukri and LinkedIn in May 2026 shows hundreds of openings in Mumbai, Bengaluru, Pune, and Hyderabad mentioning BeautifulSoup, Scrapy, or "data extraction" as a required skill.
Realistic salary bands in India for roles that use web scraping:
The best part scraping is a gateway skill. Once you can extract data, the natural next step is cleaning it, analysing it, and building models on top. Each step adds 30–50% to your market value.
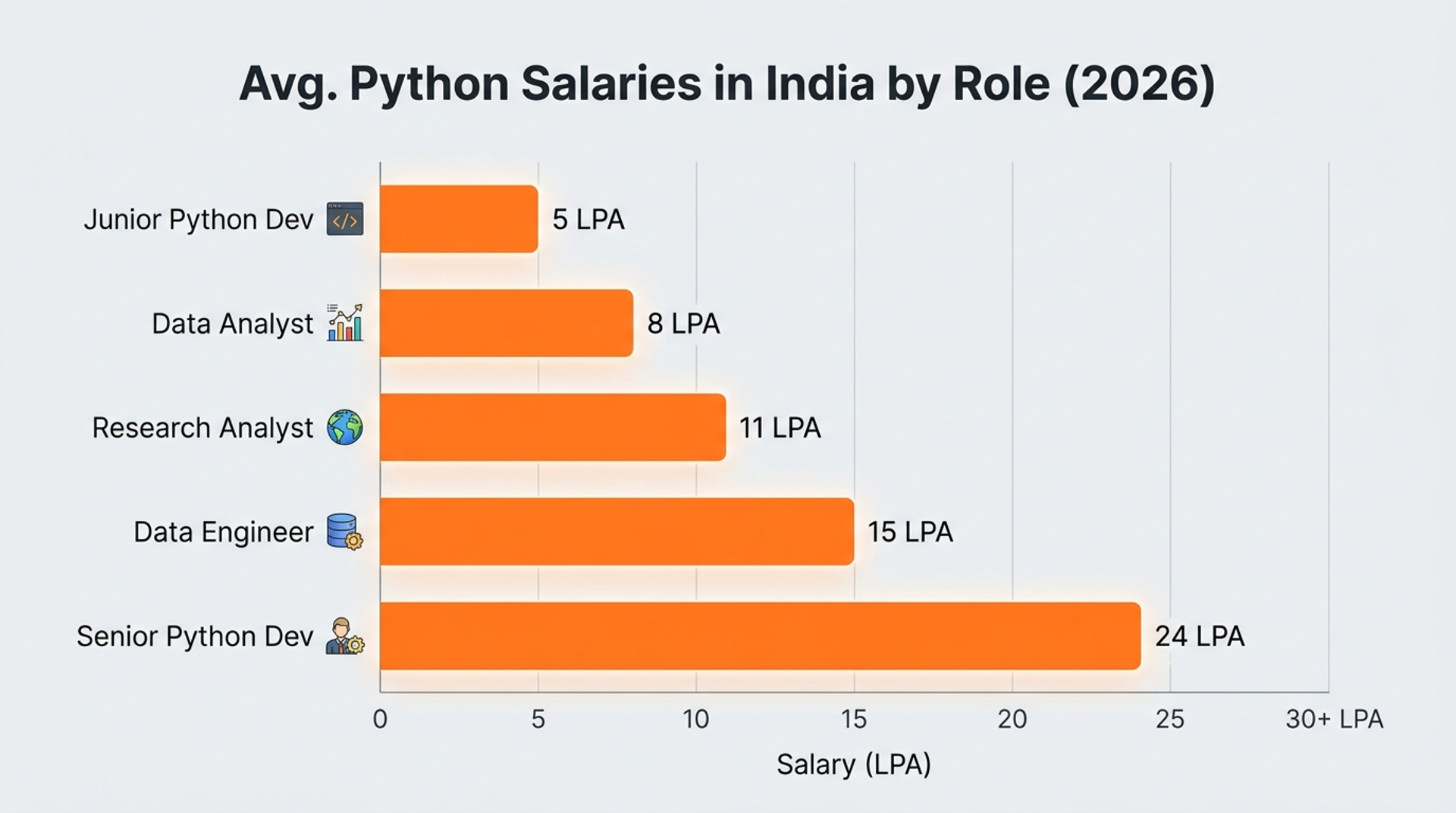
Key Takeaway: Web scraping is not a niche skill it is the entry door to a ₹10–20 LPA career ladder in Indian tech.
Once you can scrape data, the next step is cleaning and analysing it which is exactly what the Advanced Data Analytics with Python Libraries program is built around
Time to write real code. You will scrape book titles and prices from books.toscrape.com a free, public sandbox site built specifically for learners. No legal grey area, no rate limits, no ethical concerns.
Open your terminal or command prompt and run:
That's it. Two libraries, one command.
Create a new file called scraper.py and add:
A status code of 200 means success. Anything starting with 4 (like 404) or 5 (like 503) means something went wrong.
Add these lines:
You just turned raw HTML into a navigable Python object called soup.
Right-click any book on the website and select "Inspect" in your browser. You will see each book sits inside an <article class="product_pod"> tag. That is your hook.
Step 5: Extract title and price from each book
Run the file (python scraper.py) and you will see 20 book titles with their prices printed in your terminal. You just wrote your first scraper.
Add at the top: import csv. Then replace the print loop with:
Open books.csv in Excel and you have a clean spreadsheet. This is the exact pattern every real-world scraping project follows — only the website and the tags change.
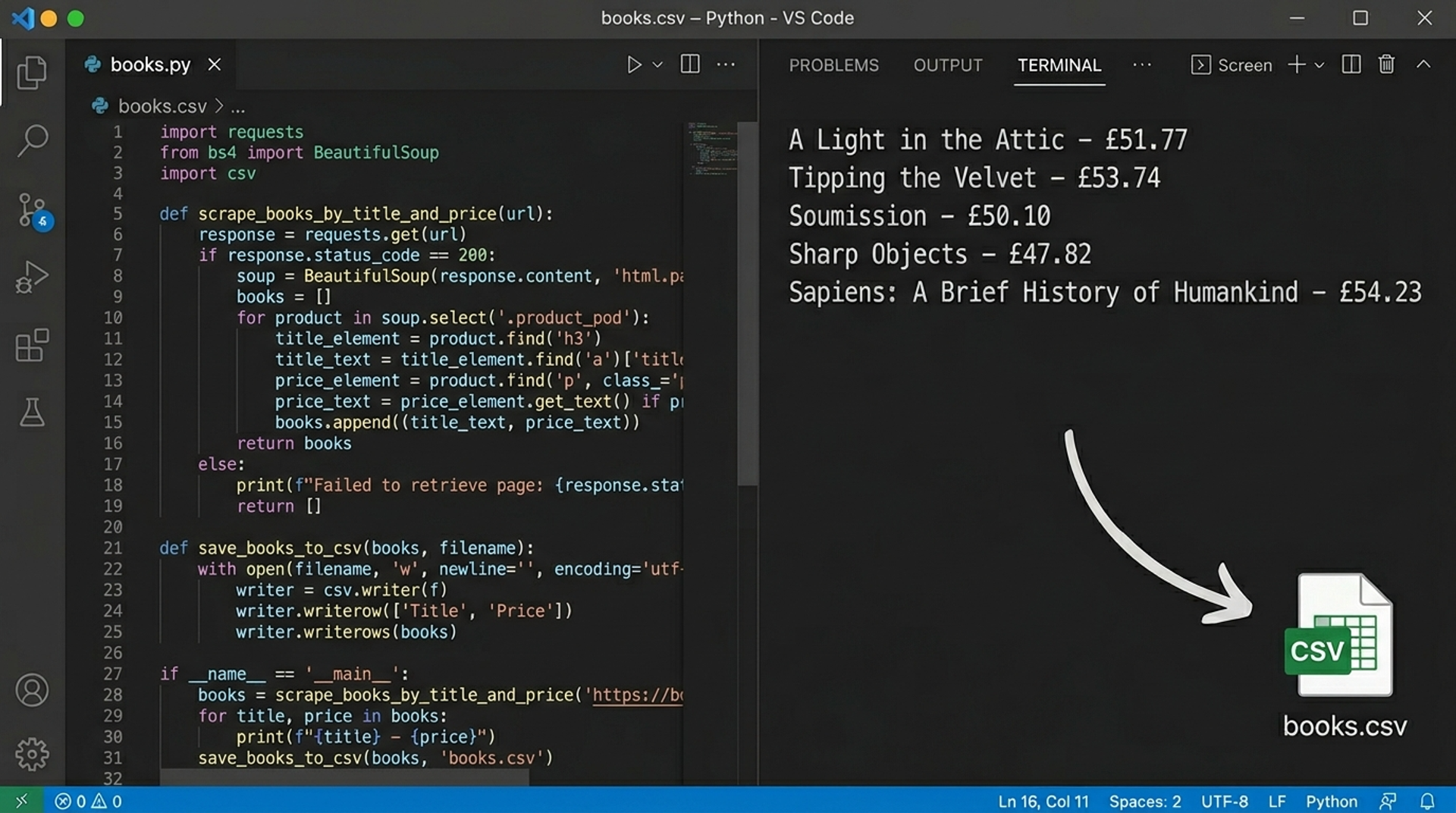
Key Takeaway: A working web scraper is literally 15 lines of Python. The hard part is not the code it is knowing which tags to target.
The code works. Now let's make sure you don't hit walls that frustrate 90% of beginners.
robots.txt Every website has a file at /robots.txt (e.g., flipkart.com/robots.txt) that lists what scrapers are allowed to access. Always check it first. Scraping disallowed pages can get your IP blocked or worse, raise legal issues.time.sleep(2) between requests. Be a polite guest, not a DDoS bot.4. Assuming the data is in HTML Modern sites like Zomato, Swiggy, and most React/Vue apps load data via JavaScript after the page loads. BeautifulSoup will not see it. For these, you need Selenium or Playwright (a topic for later).
5. Hardcoding everything If the website changes a class name, your scraper breaks. Use try/except blocks and check if elements exist before extracting them.

Key Takeaway: Good scrapers are not the fastest they are the politest and the most resilient.
Mastering BeautifulSoup is step one of a much bigger journey. Here is the realistic timeline most CDPL learners follow:
Month 1–2: Master BeautifulSoup + requests. Build 3 portfolio projects an e-commerce price tracker, a job listings aggregator, and a news headline scraper.
Month 3–4: Learn Pandas for cleaning scraped data, and learn how to schedule scripts with cron or Windows Task Scheduler. You are now job-ready for junior data analyst and research analyst roles.
Month 5–6: Move up to Scrapy (a more powerful scraping framework) and Selenium (for JavaScript-heavy sites). Add SQL to store your data properly. Salary jumps 40–60% at this stage.
Month 7–12: Layer on machine learning. Suddenly you are not just collecting data you are predicting prices, classifying reviews, and building recommendation engines. This is where the ₹15–20 LPA roles open up.
Career switchers from non-IT backgrounds typically choose the Comprehensive Data Science and AI Master Program because it bundles Python, scraping, analytics, and ML into one job-ready track.
The jobs you can target with this stack:
If you are a fresh graduate or career switcher, the fastest validated path is a structured course with live projects and placement support exactly what CDPL's Python and Data Science programs are built around.
Scraped data becomes truly powerful when you can predict and classify with it explored in depth in the Machine Learning and Data Science with Python program.
Q1. Is BeautifulSoup good for beginners?
Yes, BeautifulSoup is widely considered the easiest web scraping library in Python for beginners. Its syntax mirrors how you would describe a webpage in plain English for example, "find all article tags with class product." You can write a working scraper in under 20 lines of code, making it ideal for fresh graduates and career switchers starting their Python journey.
Q2. Is web scraping legal in India?
Web scraping itself is legal in India, but how you scrape matters. Always check the website's robots.txt file, respect rate limits, and avoid scraping personal data, copyrighted content, or pages behind logins. Public information on commercial websites is generally fine to scrape for analysis, though violating a site's Terms of Service can lead to civil disputes.
Q3. What is the difference between BeautifulSoup and Selenium?
BeautifulSoup parses static HTML that is already loaded it is fast, lightweight, and perfect for traditional websites. Selenium controls a real browser and can handle JavaScript-heavy sites like Zomato, LinkedIn, or React apps where data loads after the page renders. Beginners should master BeautifulSoup first, then add Selenium when needed.
Q4. How much does a Python web scraping developer earn in India?
Entry-level Python developers with web scraping skills earn ₹3.5–6 LPA in India. With 2–4 years of experience and additional skills in data analysis, salaries rise to ₹8–15 LPA. Specialists at fintech, e-commerce, and market research firms in Mumbai, Bengaluru, and Pune can cross ₹18–22 LPA at senior levels.
Q5. Can I learn BeautifulSoup without knowing Python?
You need basic Python first variables, loops, lists, and functions are essential. BeautifulSoup itself takes only 2–3 hours to learn once you know Python. Most beginners can become job-ready in web scraping within 6–8 weeks of dedicated practice, especially when following a structured course with live projects and mentor support.
If you are based in Mumbai, CDPL also runs an in-person Data Science Course in Mumbai with weekend batches for working professionals.
You started this guide wondering if web scraping was hard. You now have working code, an understanding of ethical scraping, and a clear career roadmap. Here are the three things to remember:
Your next move: rebuild today's scraper on a different website (try a public Wikipedia table or a static news site), then start project two. The fastest learners are the ones who write code the same day they read about it.
If you want a guided path with mentors who have built scrapers for real Indian companies, CDPL runs live, project-driven Python and Data Science batches every month with placement support and small batch sizes. Reach out, book a free demo, and see if it's the right fit. The data economy is hiring. Your move.
At CDPL Cinute Digital, we have trained 5,000+ learners across software testing, data science, and AI/ML, with 50+ active hiring partners across India
…with mentors who have built scrapers for real Indian companies read about our trainers and 15+ years of industry experience on the About Us page

A visionary data scientist dedicated to unlocking the potential of data to drive informed decision-making and spark innovation. With a strong foundation in Data Science.